
The Unscripted Curve
Innovation never follows a script. It accelerates, stumbles, and surprises. Two years ago, a leaked Google memo warned that open-source models would someday erode the moat that seemed to protect the proprietary LLM developers. For a while, the proprietary developers defied this prophecy as they raced ahead in capabilities and reputation. By now, the memo appears more right than the worst-case projections of the time. More importantly, few could have predicted the kind and the quantity of parties that would seize the moment.
A year ago, the idea of Chinese leadership in AI sounded implausible. Our series of articles, starting with the one titled A Quiet Surge: the Rise of Chinese AI innovators generated more doubts about the content than reviews of the landscape. Even after DeepSeek, the world assumed China’s models were derivative or copies, with unprovable, exaggerated claims, its labs constrained by sanctions and costs.
That view now feels dated. By mid-2025, Chinese developers released more public LLMs than anyone else. They have begun to dominate download charts. DeepSeek, Qwen, MiniMax, and Kimi are no longer marginal names. This reversal began before the latest releases that appeared in recent weeks. When we began writing the article earlier in the week, eight of the ten highest-scoring open models were Chinese. If one can believe it, the lead has since widened! While we were writing, just on this Friday, we got the first open-source model, this one from Kimi, that claims to surpass the capabilities of the best proprietary models across a list of popular benchmarks. The change is no longer just about algorithms. It is about how the economics of AI will undergo more changes in 2026.
The Cascade Westward
Before we discuss the details of changes afoot, let’s look at the evidence of acceptance. For a host of nationalistic, idealistic, historic, and other reasons, the Chinese models have attracted scorn in popular media in their cost claims, security and privacy issues, the genuineness of innovations claimed, and the legality of the hardware that may have been used. None of these questions is adequately answered or answerable to the satisfaction of all, but in many Western quarters, skepticism didn’t end with an argument. It ended with usage.
As per media reports, Cursor’s engineers now rely on Chinese open models to power their code-generation agents. Cognition’s frontier-sized SWE-1.5 was quietly built on a Chinese base model. Airbnb, once expected to lean toward OpenAI, runs its customer service bots on Alibaba’s Qwen. A fortnight ago, its chief executive, Brian Chesky, called it “fast, good, and cheap.” Chamath Palihapitiya, founder of Social Capital, has stated that some of his companies moved multiple workloads from Anthropic and OpenAI to Moonshot’s Kimi, calling it “way more performant and a ton cheaper.”
One can dismiss the recent news of Chinese models beating other models in crypto and stock trading (separate tests reported here and here) one-off, idiosyncratic, and without sufficiently long history. However, the evidence of parity is growing.
What one is witnessing in the production adoption of a small number of US companies has long-term implications. Models once dismissed for security or reliability issues now anchor businesses that would not switch their preferences without advantages too huge to ignore. Clearly, doubts about backdoor leakages or state subsidies fade when efficiency wins.
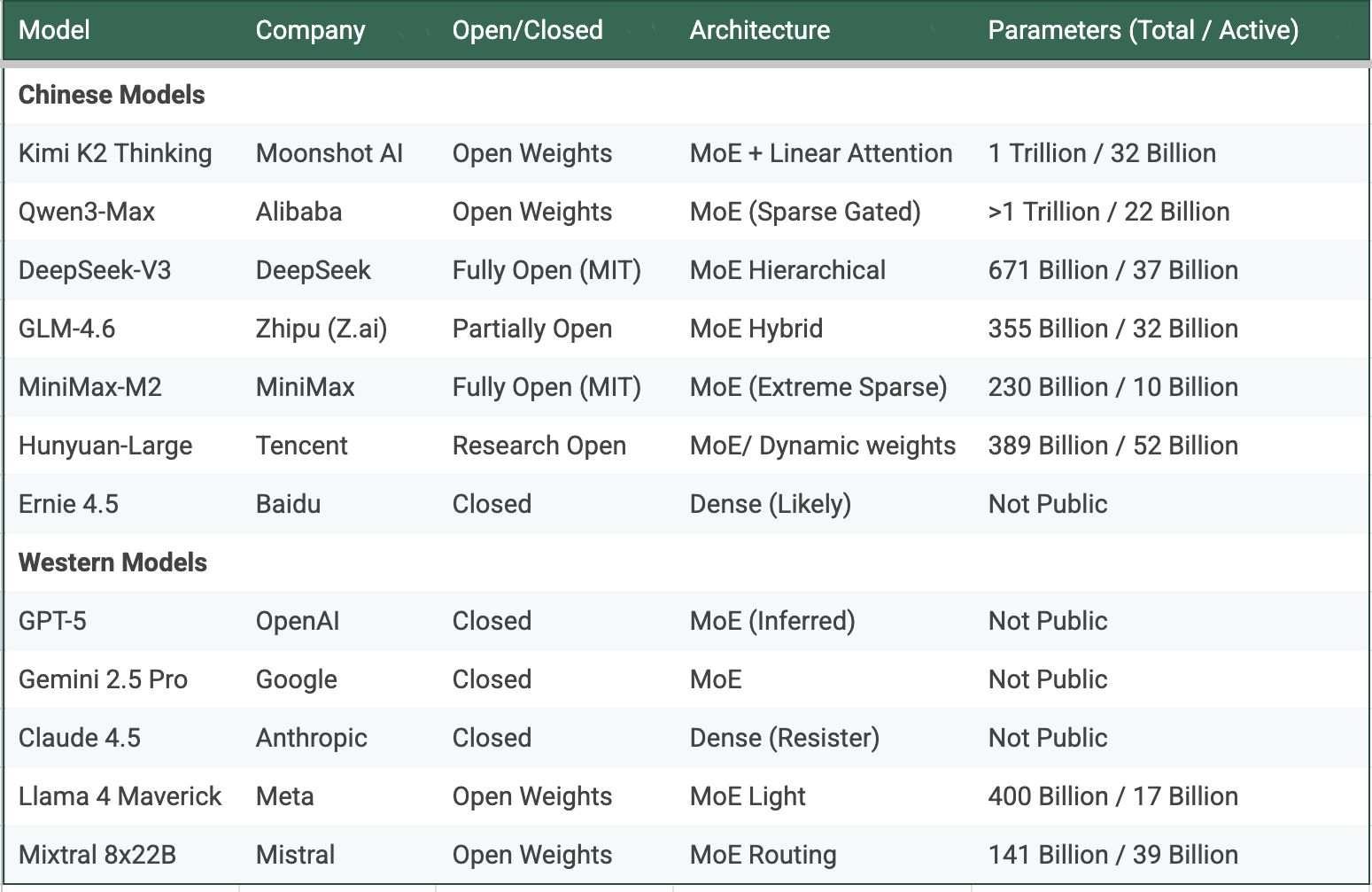
Chinese models are setting new norms and new transparency standards. Every major Chinese release arrives with a paper, a benchmark, and weights that can be downloaded by anyone without any fees or fine-print conditions.
Architectures in Motion
At the heart of this surge is one principle: do more with less. The technology underpinning this new wave is the Mixture of Experts (MoE). The simple takeaway is this: Chinese models have universally adopted MoE. They are now innovating within this framework, creating relentless new waves of efficiency. In contrast, a few key Western models, like Anthropic's Claude, are resisting MoE entirely. Others have adopted it, but without the same obsessive focus on efficiency. In China, the race is now against each other. The number of new directions, the speed of announcements, and the quality of execution are breathtaking. The rest of the section is skippable for those not interested in the broad details of MoE.
For those interested in the details, it helps to understand the context. Most observers follow AI development in broad strokes. The first wave, in 2023, was about size. It was a race for ever-larger models. The second wave, in 2024, was about Reasoning, as "Chain of Thought" techniques became standard. Many adopted this shift quickly. Some, like Llama and Mistral, missed a beat and suffered enduring consequences. The broad stroke of the current period is this Mixture of Experts.
This method, which originated at Google, is an efficiency strategy. The MoE turns a single massive model into a federation of smaller ones. Instead of lighting up all parameters for every query, MoE activates only the experts needed for a given task. The rest stay idle, cutting costs without shrinking total scale.
MoE’s genius is that it invites variation. Once a model becomes a collection of specialists rather than a single monolith, each lab can decide how to slice and assign those specialists. Some cluster by skill, where one group of experts could be for language, another for math, and another for reasoning. Others may distribute by depth with light experts for fast answers, heavy ones for complex tasks. Some, like MiniMax, switch experts dynamically within a single query, treating each step as a separate routing problem. DeepSeek groups its experts hierarchically, passing partial results up a tree until the best layer completes the answer. Qwen pursues efficiency through “sparse gating,” allowing multiple tiny experts to share activation slots so that no compute ever idles. Kimi, the most recent, mixes modular routing with long-context attention, calling different experts for each stage of a reasoning chain.
These design choices sound like jargon, but they translate to visible gains. Faster models. Lower cost. Longer context windows. In one generation, Minimax has exhibited extreme sparsity, achieving top performance by activating only 10 of 230 billion parameters. Kimi is mixing MoE with new attention mechanism that seems to grow linearly, as against quadratically for the traditional transformers, promising extreme gains for long context. DeepSeek is re-engineering core expert-routing logic itself while Tencent shocked everyone recently with the concept of non-fixed weights.
Chinese teams have shown that there is no single best MoE recipe—only endless ways to mix experts. Each permutation unlocks another small leap in efficiency or reasoning depth.
The wider lesson is that MoE proves how far the field still is from the theoretical limits of the transformer. The pace of progress points that current architectures are unlikely to be anywhere near a final, optimized design. The prevailing belief that scaling size alone guarantees progress is passe. MoE is a reminder that heuristics, not laws, guide this science. There is no fixed path. Efficiency breakthroughs may come from routing, sparsity, memory, or something not yet imagined. The only certainty is that where more methods are being explored, there is a higher probability of a breakthrough. China is, right now, the center of that exploration.
Economics of Openness
Open source does not mean zero revenue. It changes where revenue comes from.
Running a large model still needs compute. Hosting an open model at enterprise scale demands racks of GPUs or access to cloud capacity. The capital cost shifts from license to infrastructure. For most users, that trade-off favors paying the model’s creator for API access rather than self-hosting.
That is the hidden business model of openness. Free cognition, paid convenience.
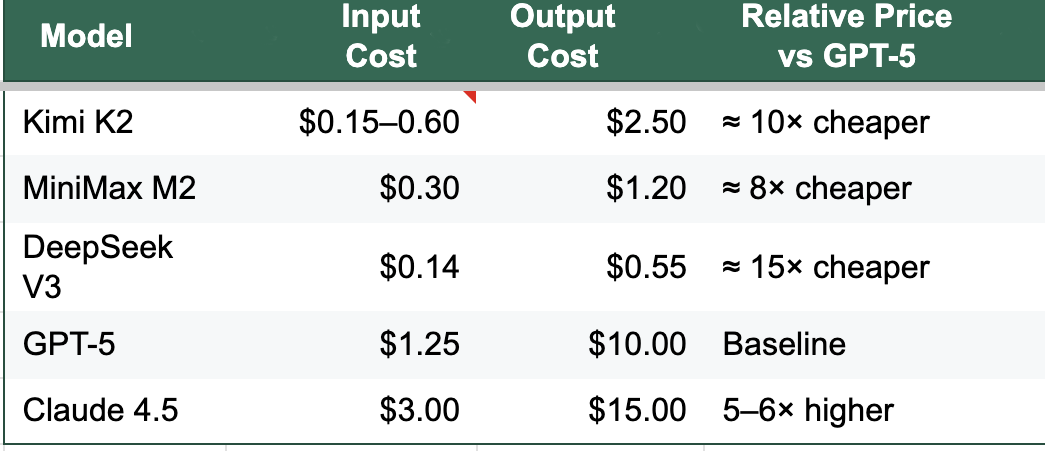
DeepSeek’s 671 billion-parameter model cost under six million dollars and the same number is going around for the latest Kiimi model that is going head-to-head with OpenAI’s best in the popular benchmarks. Irrespective of whether the actual training costs are what is believed or a few times more, these models are trained extremely cost-effectively. As a result, Chinese teams can charge pennies and still earn margins. Their APIs are ten to fifty times cheaper than Western equivalents. They need fewer users to break even.
The Cost of Cognition (Per 1 Million Tokens)
The New Brutality
Competition has turned from symbolic to existential. Chinese labs ship new models every few weeks, often with measurable gains. As we witnessed in recent days, some Western model developers have begun lobbying for policy protections. The real consequence, however, is that given the intensity of innovations and progress, none of the major regional innovation centres or corporate teams can afford to go slow on their efforts. If some are failing miserably on cost benchmarks, they will need to find other innovation winners in capabilities.
It is not a surprise that Jensen Huang feels China is nanoseconds behind in AI. Even with hardware restrictions, its innovation engine has shown no signs of struggle. Some would argue that the curbs have only made them more focused on efficiency.
Prima facie, we believe that improving efficiencies multiplies demand. Each improvement in model cost invites new uses: video generation, multimodal search, and autonomous agents. A single thirty-second video can consume more compute than pages of text inference. That said, we will be the first ones to believe in any such hypothesis simply on the back of “feelings” or “history” or a fancy-named law.
As we stare at the arrival of 2026, two massive races are gathering intensity. One is in the model developments described above, and the other is in the design of custom chips. The players in the chip race, as described somewhat in the middle section of this note, involve the world’s biggest hardware names with the biggest budgets. And Google’s Ironwood TPU announcement a couple of days ago showed that it, too, could provide surprises nobody can predict.
The simple truth is that predictions are dangerous. No one foresaw Chinese open weights becoming the world’s benchmark leaders. No one can know which innovation thread will dominate next year.
The only durable rule is flexibility. At GenInnov, we keep reminding ourselves to learn from events as they unfold rather than expect them to follow any particular path. Evidence-based investing requires one to remain flexible in selecting or exiting, and to keep learning, irrespective of how complex it may appear.


