
Whiskey Problem and The Vintage Trap
In the early 2000s, the world of fine spirits broke. Demand for aged whiskey and fine wine exploded with new wealth, new buyers, and a global culture shift. Everyone could see it. But supply couldn’t respond, because supply had been “decided” years earlier, when the barrels were filled. No amount of money could speed up a calendar. The result was violent. Prices didn't just rise; they decoupled from reality.
Today, we are walking into the exact same trap. But this time, it isn't about luxury consumables. It is about the fundamental substrate of the modern economy.
It is about silicon.
We are witnessing a Silicon Shock. It is happening now. It is happening at a scale that makes the whiskey crisis look like a rounding error. And unlike the 1970s oil shocks, which were driven by supply embargoes, this crisis is driven by a ferocious, unyielding explosion in demand.
The world has suddenly realized it needs to convert sand into "intelligence" at a rate that defies physics. The demand for compute, specifically, the high-performance silicon required to process AI tokens, has not increased by 50% or 100%. Depending on how you measure the "token,” the fundamental unit of AI thought, demand has exploded by anywhere from 40x to 100x in the last 18 months. One credible synthesis puts monthly tokens at roughly ~40 trillion (2024) to ~4 quadrillion (late-2025) or about ~100×. Even if you cut the headline and use a more conservative blend, you still land in the ~40-60× (annualized blending) range, with peak bursts higher.
The supply chain cannot hold. It is breaking. The wafers, the memory, the advanced packaging that transforms raw silicon into AI accelerators cannot respond to demand shocks measured in decades-per-quarter. Building a new fab takes 3-5 years. Expanding high-bandwidth memory production takes 2-3 years. Adding advanced packaging capacity takes 18-24 months. After exhausting spare capacity and drawing down inventories to crisis levels, the world has reached a point where the bottlenecks are multiplying.
The narrative that this is a "financial bubble" ignores a far bigger reality. Even if all the suspect initiatives or accounting trickeries are reversed instantaneously, the demand explosion has little to do with their activities.
Extremely simplistically, what we show below is that if tokens rose ~100× and efficiency improved ~20×, you still get ~5× net silicon demand at the most advanced logic and memory levels. And, the supply base at the critical bottleneck points grew roughly ~1.5× to 2×. The realities becoming obvious daily are that the advanced packaging lines at TSMC and the memory production facilities of the three makers are already fully booked for 2026, and with no respite in parabolic demand, they are looking to pay higher prices to cut the queue.
So, we are entering 2026 with a silicon deficit that money, politics, or clever engineering cannot solve. The die is cast. The shortage is here. And just like the oil shocks of the past, the pain is about to cascade from the data center down to your laptop, your phone, and your wallet. Both expose the same vulnerability—profound dependence on concentrated, inelastic supply chains for foundational economic inputs. And, the silicon shock may prove more persistent as what is planned for supply does not remotely look like matching the sharply exploding demand even now.
The Token Explosion: AI Leaves the Chatbox
The primary reason the market has miscalculated the severity of this shock is a fundamental misunderstanding of what is consuming the silicon.
For most of 2023 and 2024, the mental model for AI demand was "human-speed" interaction: A user types a prompt into a chatbot. The chatbot replies. The transaction ends. This linear relationship of one human, one query created a predictable, albeit steep, demand curve.
That era is over. In late 2025, the nature of the workload shifted fundamentally. We moved from Chatbots to Agents, and from Pattern Matching to Reasoning.
The new dominant workload is "Agentic AI." These systems do not wait for a prompt. They run in continuous, autonomous loops, planning, executing, checking, and correcting. A single instruction from a human ("Plan a marketing campaign") can trigger a cascade of thousands of internal inference steps, running 24/7, invisible to the user but punishing to the hardware.
Simultaneously, the integration of AI into "default" surfaces from Google Search and Microsoft Office to WeChat or summarizers in every application has converted billions of trivial, low-compute interactions into heavy, high-compute inference tasks.
METHODOLOGICAL CAVEAT: THE ESTIMATES PRESENTED BELOW INVOLVE SUBSTANTIAL UNCERTAINTY. TOKEN COUNTS ARE NOT STANDARDIZED ACROSS PROVIDERS; "REASONING TOKENS" MAY INFLATE VOLUMES RELATIVE TO "OUTPUT TOKENS"; CHINESE DISCLOSURES MAY NOT BE DIRECTLY COMPARABLE TO WESTERN METRICS; AND SYNTHETIC DATA GENERATION BLURS THE LINE BETWEEN TRAINING AND INFERENCE. WE PRESENT WIDE RANGES THROUGHOUT AND ACKNOWLEDGE THAT REASONABLE ANALYSTS COULD ARRIVE AT DIFFERENT FIGURES USING DIFFERENT ASSUMPTIONS. THAT SAID, THE DIRECTIONAL CONCLUSIONS ON EXPLOSIVE DEMAND GROWTH, STRUCTURAL SUPPLY SHORTFALL, CASCADING PRICE EFFECTS ARE CORROBORATED BY OBSERVABLE MARKET EVIDENCE: SOLD-OUT CAPACITY, RATIONING BEHAVIOR, AND TRIPLE-DIGIT PRICE INCREASES. THE RANGES SHOULD BE READ AS APPROXIMATE GUIDES TO MAGNITUDE, NOT PRECISION ESTIMATES.
The shift in compute intensity
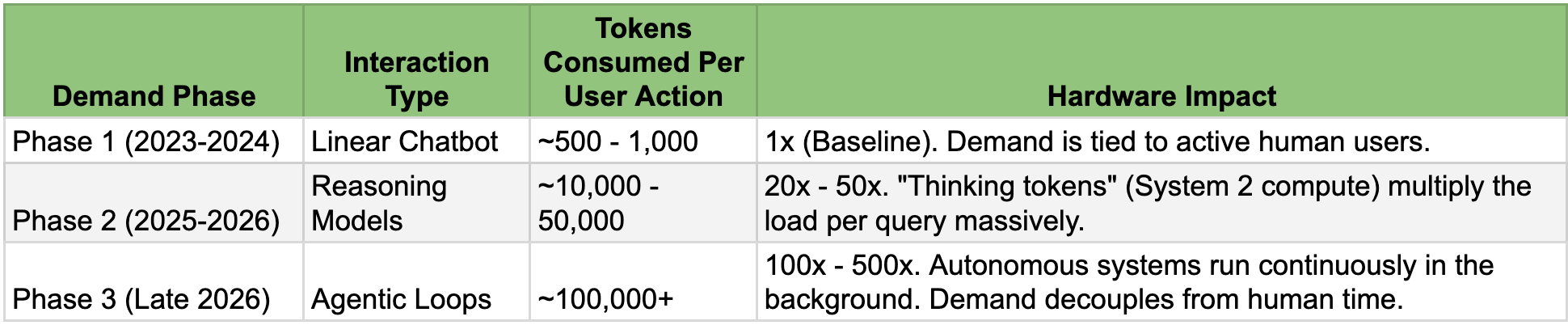
The "invisible" tokens are the ones breaking the supply chain. When a reasoning model "thinks" for 20 seconds before answering, it is burning silicon capacity that simply didn't exist two years ago. When Google switched its Search AI Overviews to reasoning-enhanced models, it applied compute-intensive inference to 4+ billion daily queries. A single decision converted low-cost keyword lookups into high-cost generative tasks. Multiply this across Microsoft's Copilot in Office, Meta's AI in WhatsApp, Apple's Intelligence in iOS, and Tencent's agents in WeChat, and the aggregate demand becomes astronomical.
Select examples of how AI use cases are exploding outside chatboxes
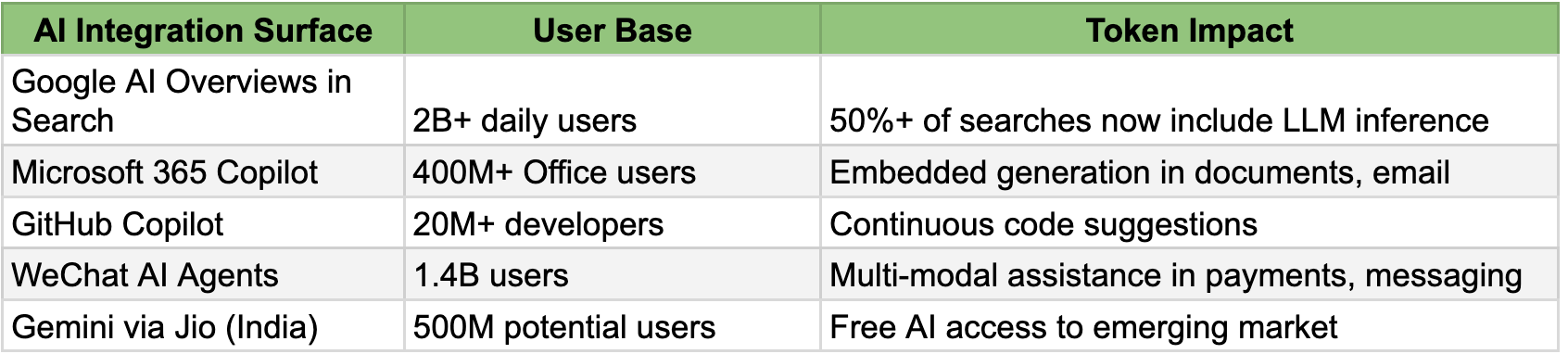
Some observers may dismiss the silicon shock as the frothy excess of an AI bubble or overinvestment by hyperscalers chasing speculative returns, destined to collapse when ROI fails to materialize. This critique misunderstands the nature of the demand. What the above tables highlight is that this shortage is not speculative buildout of empty data centers on cheap financing. It is operational inference load from real users generating real tokens in real applications. Even if some hyperscaler capex proves excessive, the underlying inference demand continues growing. AI is not a product that will be abandoned when funding tightens; it is becoming infrastructure, embedded into the operating rhythm of billions of workflows.
The Token Math: Quantifying the Impossible
Attempting to quantify this explosion requires navigating a fog of proprietary data, but the signals leaking from the hyperscalers are consistent and terrifying.
Google’s internal data offers the clearest window into the scale of the shock. In early 2024, their monthly token processing was manageable. By late 2025, driven by the rollout of Gemini into Search and Workspace, the numbers went vertical.
Select examples of the trajectory of token demand (based on where information is made available)
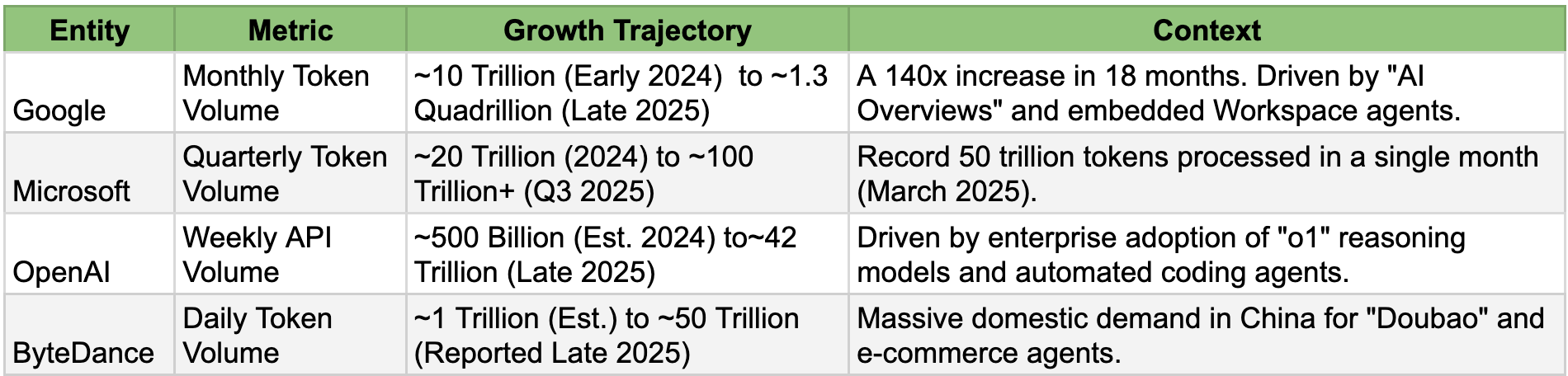
Source: Derived from Google I/O 2025 disclosures, Microsoft Q3 2025 earnings transcripts, and 36Kr reporting.
The math is brutal. Even if we strip away the outliers and assume a conservative industry-wide growth rate, we are looking at a 30x to 50x increase in raw demand. The physical infrastructure to support this does not exist.
Token growth by demand layer (monthly run-rate)
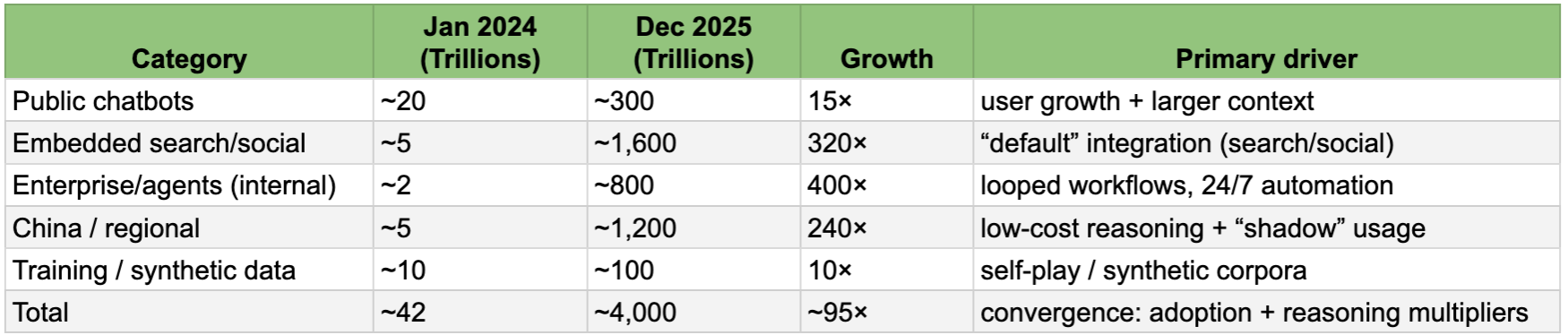
The Capability Deflator: Why 100x Demand ≠ 100x Silicon
A common counter-argument is that hardware is getting more efficient. This is the "Capability Deflator." If token demand grew 50-100x and the world didn't collapse, how much actual silicon growth was required? The answer lies in compounding efficiency gains across hardware and software.
For example, it is true that an Nvidia Blackwell (B200) chip is significantly more efficient than the previous generation H100. It delivers more tokens per watt and per dollar. Software optimizations with examples like quantization, speculative decoding, Mixture of Experts (MoE) have also squeezed more performance out of existing silicon.
Gains from these efficiency gains are mindboggling on their own. Every new instance of NVIDIA or AMD’s chips, for instance, deserves all the plaudits they get for the multiplicative efficiencies they generate.
However, in the face of 100x demand growth, a 20x efficiency gain would also be grossly inadequate. It merely delays the inevitable by a few months. This is Jevons Paradox on steroids: as compute becomes cheaper and more efficient, we find exponentially more ways to use it.
Estimates of capability improvements, aka capability deflator
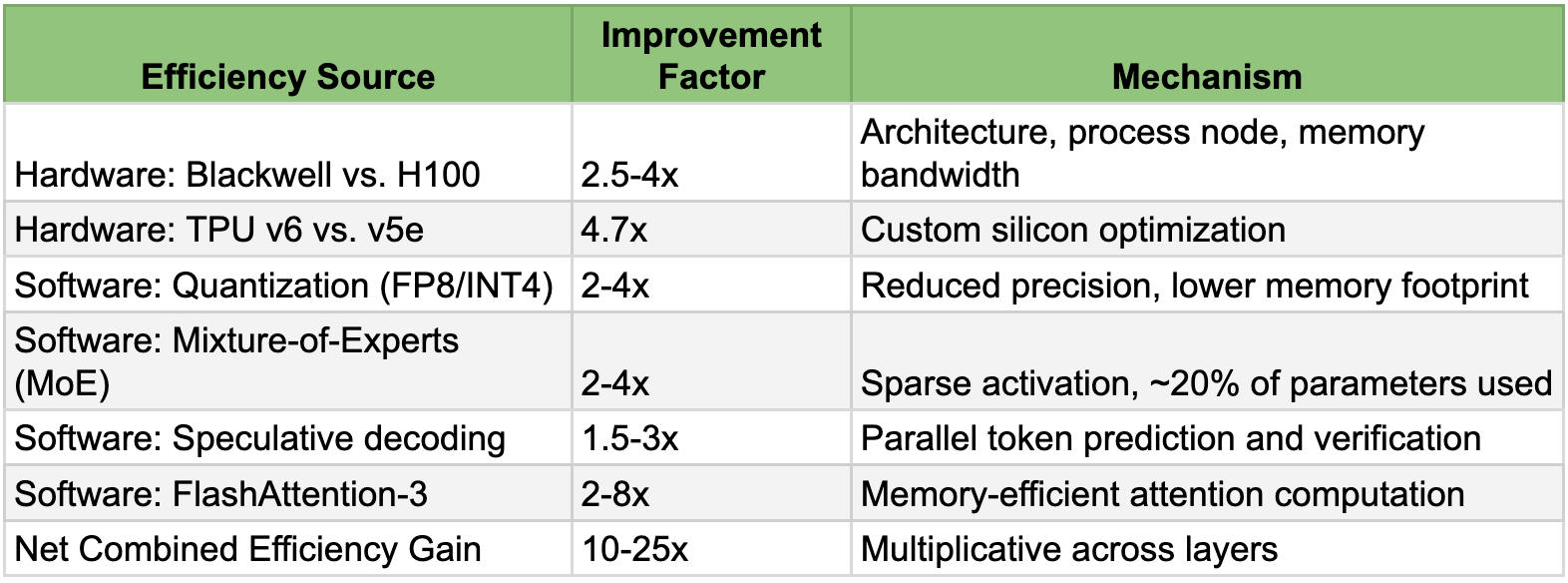
These gains are real and substantial. But efficiency remains a deflator, not a solution.
We have hit the physical wall of unyielding bottlenecks. The bottleneck is not just about "chips." It is a complex, interlocking failure of three specific technologies that cannot be scaled overnight: High Bandwidth Memory (HBM), CoWoS Advanced Packaging, and Foundry Capacity.
The supply chain choke points (2026 status)
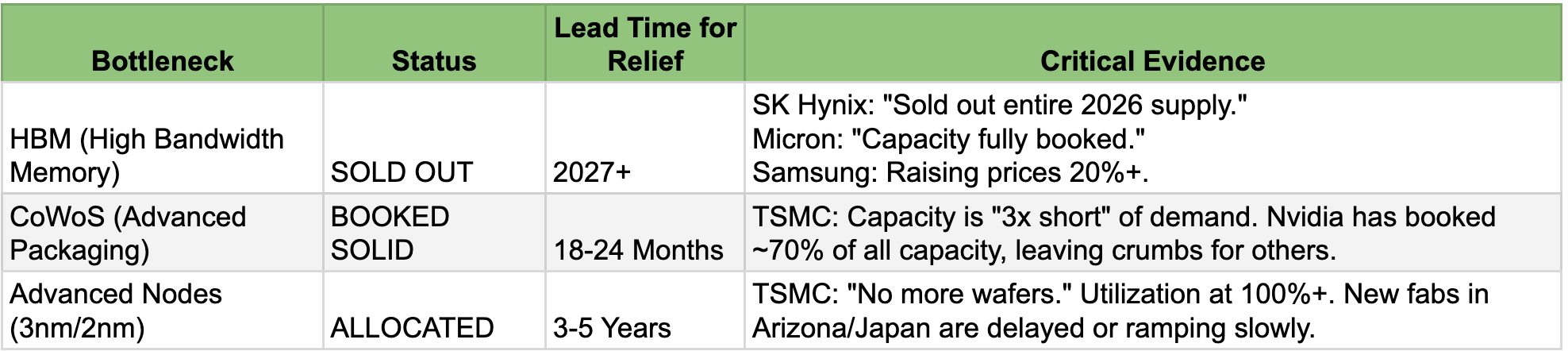
The reality for 2026 is simple: The capacity does not exist. The factories required to solve this problem have not yet been built. What is being planned for the coming years, as of now, are also remotely not sufficient if demand growth remains on the same trajectory.
The Cascade Effect: The Vampire Economy
The most insidious part of the Silicon Shock is the Cascade Effect. Because AI demand is effectively infinite and price-inelastic (hyperscalers will pay anything to secure supply), the semiconductor industry has rationalized its entire production line to serve AI.
Samsung and SK Hynix are actively converting production lines away from standard consumer memory (DDR4/DDR5) to make HBM. This is the "Vampire Effect": AI is sucking the lifeblood out of the rest of the electronics market.
The result is a shortage of the "boring" chips used in laptops, phones, and cars. Prices for standard RAM are skyrocketing because the wafers are being used for AI instead.
The cascade mechanism
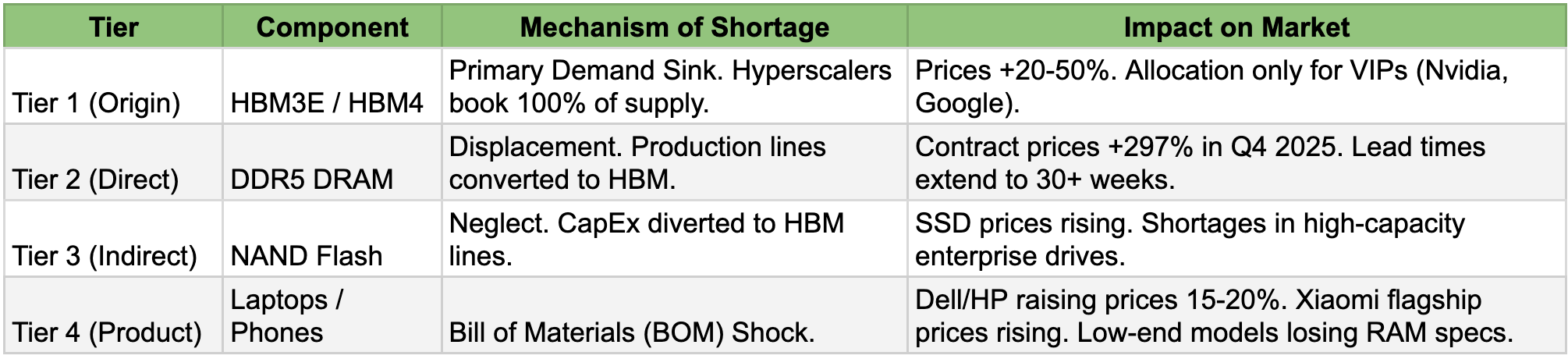
Industry DRAM inventory levels fell from 13-17 weeks in late 2024 to just 2-4 weeks by October 2025. This is crisis territory. There is no cushion remaining. With memory consuming 15-20% of device bill-of-materials costs—up from 8-9% last year—OEMs face impossible choices: raise prices, cut specifications, or compress margins to zero.
OEM responses to memory cost surge.
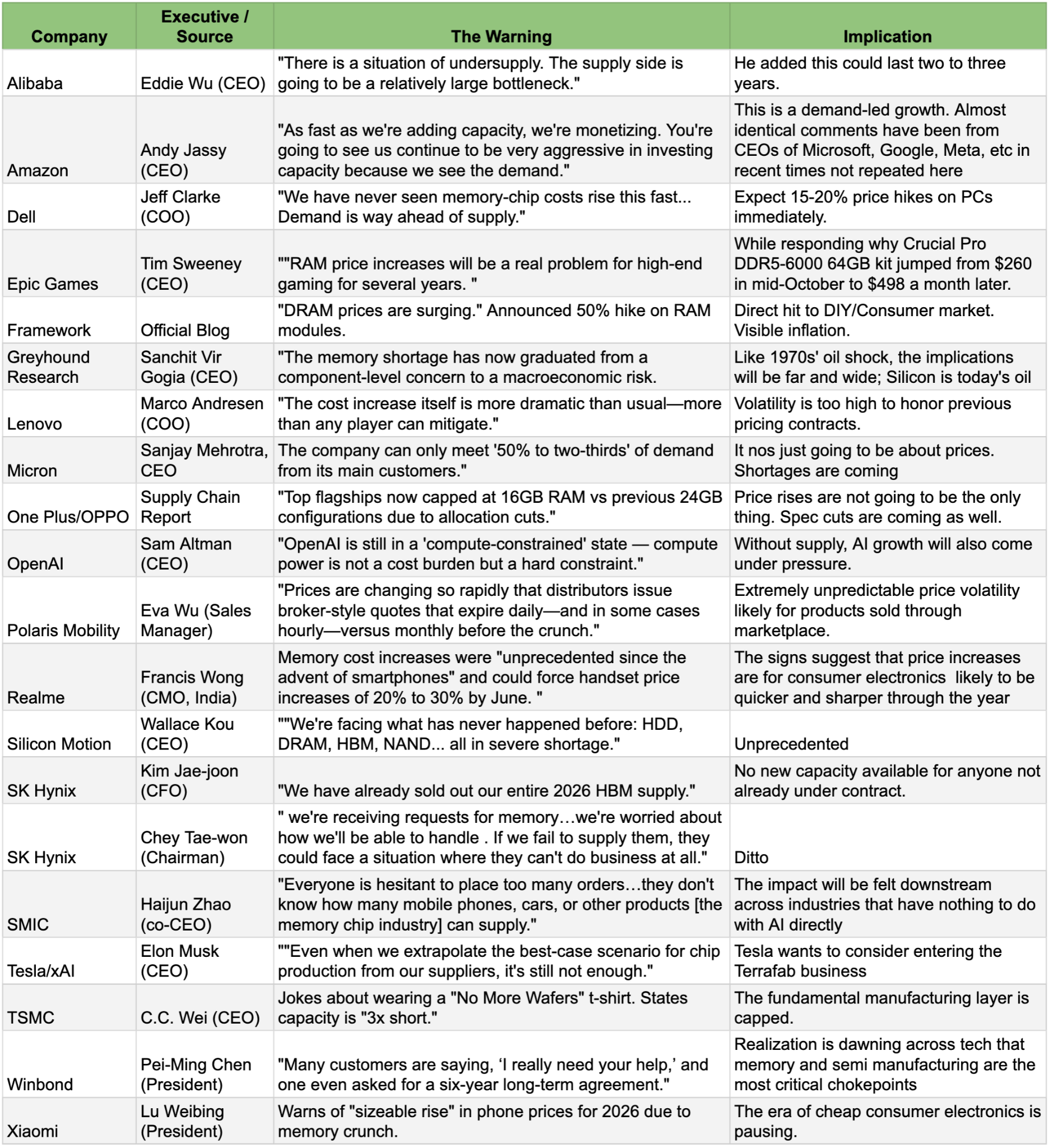
The Executive Chorus: Warnings from the Front Line
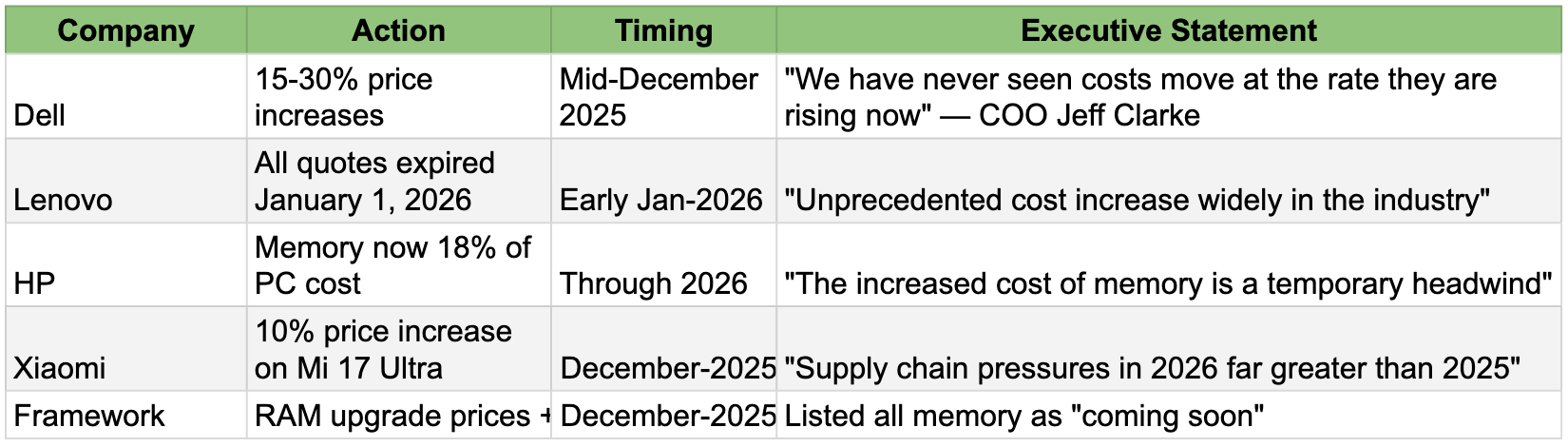
In the last few weeks of 2025, the whispers turned into screams. Executives across the hardware spectrum began issuing stark warnings to their partners and investors. They are no longer hiding the problem; they are pricing for it.
The senior executive warnings (only November or December 2025)
The Holiday Acceleration: 2026 Begins with Fire
Developments over the recent holiday period have only confirmed that the snowball is accelerating. Any hope that the end of the year would bring a cooling-off period has been dismantled by a series of critical updates. For instance, reports confirm that Nvidia has received approval to export the H200 chip to China. This is a massive demand injection. Each H200 requires six stacks of HBM3E. NVIDIA is reportedly fulfilling initial orders from inventory but is aggressively approaching TSMC to ramp production. This effectively drains any lingering HBM3E spot supply, further tightening the noose for 2026.
Sources indicate that Samsung and SK Hynix are preparing to pivot production to next-generation HBM4 in late 2026. This creates a dangerous "air gap" for HBM3E supply. As lines are shut down for retooling, the supply of the current standard (HBM3E) used by Nvidia’s H200 and Google’s TPU v7 will contract just as demand peaks. This has emboldened suppliers to raise HBM3E prices by ~20% for 2026 contracts, a virtually unheard-of move for a "maturing" product.
Conclusion: The Oil Shock of the 21st Century
As we kept paying attention to experts talking about the AI-overinvestment and pessimists pointing to surveys of consumer or industrial lacklustre attitude towards AI, something exploded nearly 50, or possibly 100 times. The explosion is not from a low base. Eighteen months ago, the worriers were already raising US$600bn question.
As we discussed in our piece Tech is Dead as We Know It in the section titled “Hardware is Dead as We Know It,” the AI compute cannot happen on our existing devices like mobiles or laptops; they are turning into dumb terminals for the new processes, almost like calculators when one had to do the spreadsheet work.
The crunch has been developing for a while, and now it may appear like it is reaching a crescendo. Absolutely not. We might be the first one to compare Silicon Shock with the Oil Shock with a table like below, and we most likely will not be the last one. But the point is not recognition of this phenomenon, but the fact that this is going to turn materially worse for at least two years.
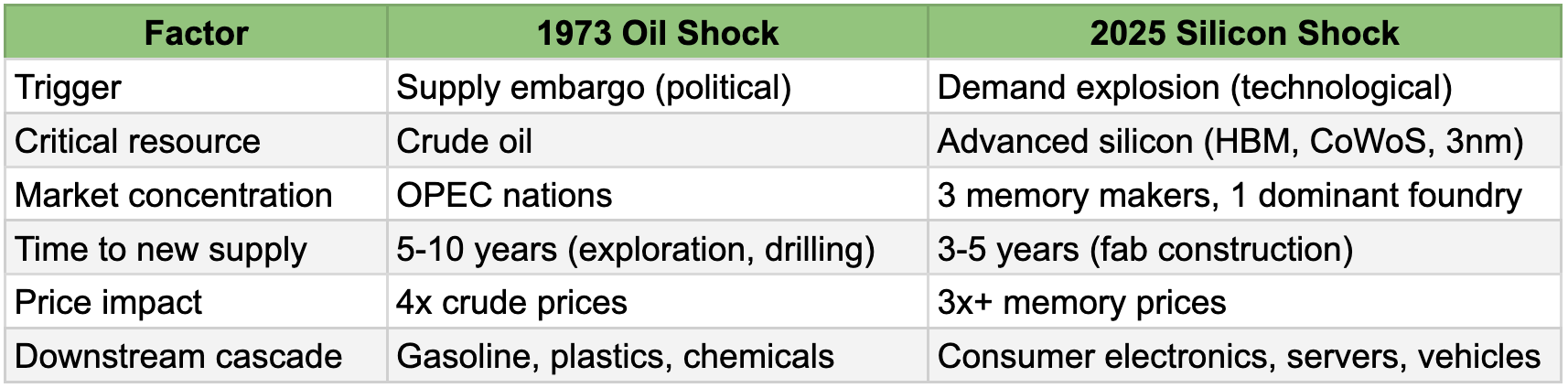
One can come up with a long list of things to show how the two are not at all same, or whether any tech product price or availability crunch could be as bad as what 1970s’ generation had to experience. What is becoming undeniable is that we are staring down the barrel of a supply chain crisis that looks less like a tech cycle and more like a geopolitical resource shock with substantial macro and micro implications.
One has heard a lot about the Power Wall, or power shortages for AI centres, in recent quarters. These are, to some degree, solvable problems with human ingenuity or top-down regulatory clamp-downs. We cannot think of any half-decent solution for the Silicon Shock the world has entered into.
Silicon may or may not be the new oil, but Silicon Shock has the potential to be a dominant macro, political, and market theme of 2026.


